
Light Field Networks, the re-formulations of radiance fields to oriented rays, are magnitudes faster than their coordinate network counterparts, and provide higher fidelity with respect to representing 3D structures from 2D observations. They would be well suited for generic scene representation and manipulation, but suffer from one problem: they are limited to holistic and static scenes. In this paper, we propose the Dynamic Light Field Network (DyLiN) method that can handle non-rigid deformations, including topological changes. We learn a deformation field from input rays to canonical rays, and lift them into a higher dimensional space to handle discontinuities.
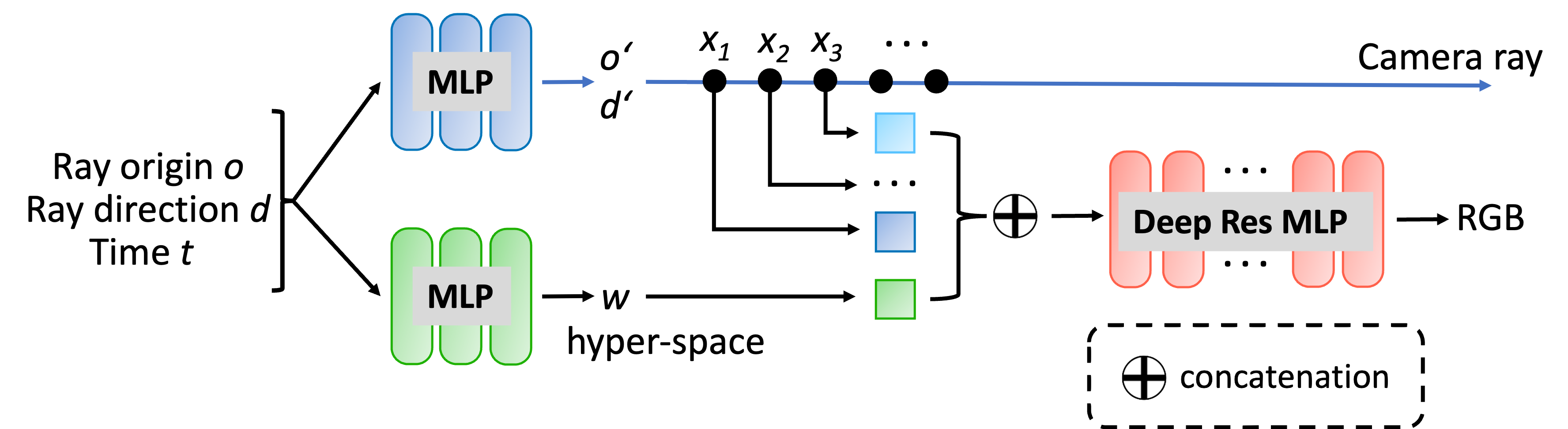
Schematic diagram of our proposed DyLiN architecture. Given a ray r = (o, d) and time t as input, we deform r into r' = (o', d'), and sample few points xk, k = 1, . . . , K along r' to encode it (blue). In parallel, we also lift r and t to the hyperspace code w (green), and concatenate it with each xk. We use the concatenation to regress the RGB color of r at t directly (red).
We further introduce CoDyLiN, which augments DyLiN with controllable attribute inputs. We train both models via knowledge distillation from pretrained dynamic radiance fields. We evaluated DyLiN using both synthetic and real world datasets that include non-rigid deformations of varying difficulty and type. DyLiN qualitatively outperformed and quantitatively matched state-of-the art methods in terms of visual fidelity, while being 25−71× computationally faster. We also tested CoDyLiN on attribute annotated data and it surpassed its teacher model.
Below demonstrates the rendering quality and speed of our DyLiN method (Right) compared to HyperNeRF (Left), the previous state-of-the-art, on real scenes.
We also tested DyLiN on synthetic scenes. In addition to significantly faster render times, we achieve superior fidelity! Results are played at the same FPS with the actual speed noted above.
To get the CoDyLiN architecture, we directly added masks to signify which regions of the scene are controllable and attribute values for the state of the transition, with -1 being the start of the transition and +1 being the end. With the addition of both of these elements to DyLiN, we can fully control the smile, closing of the eye, and raising of the eyebrow
@article{yu2023dylin,
title={DyLiN: Making Light Field Networks Dynamic},
author={Yu, Heng and Julin, Joel and Milacski, Zoltan A and Niinuma, Koichiro and Jeni, Laszlo A},
journal={arXiv preprint arXiv:2303.14243},
year={2023}
}
This research was supported partially by Fujitsu. We thank Chaoyang Wang from Carnegie Mellon University for the helpful discussion.


